
Fueled by the recent May FHIR Connectathon, Dynamic Health IT (DHIT) has renewed our focus on leveraging FHIR to solve our customer’s use cases:
- ONC Certified EHR products will be required to support Bulk FHIR under the new 170.315(g)(10): “Standardized API for Patient and Population Services”.
==> Deadline for Rollout: End of 2022
- Electronic Clinical Quality Measures (eCQMs) are moving toward using FHIR as a data source. Read more in our blog, FHIR Connectathon: Clinical Reasoning.
==> Timeframe: No deadline yet. Should happen over the next few years.
The 170.315(g)(10) Standardized API criterion dramatically expands required functionality for EHR vendors. Prior to (g)(10), APIs only had to provide data for one patient at a time, limiting the utility of APIs to personal health record (PHR) apps and not much else. (g)(10) requires EHRs to support queries for data from multiple patients, supporting use cases such as “Give me USCDIv1 data for all patients discharged from January 1st through March 31st” or “Give me the problem lists for all patients with PCP doctor Susan Smith”, and even mass data dumps for EHR conversions.
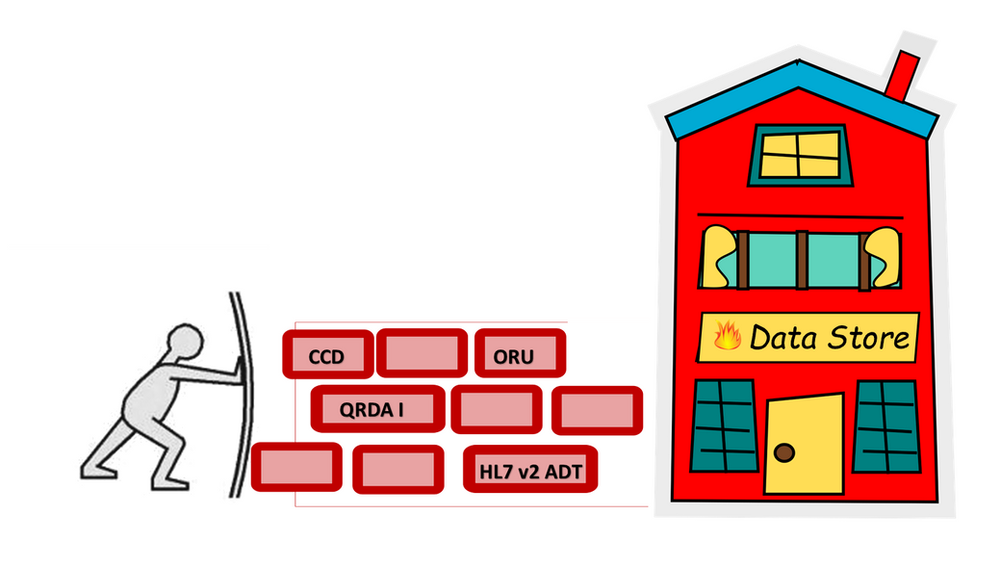
DHIT Embraces Bulk Data
To accommodate (g)(10), DHIT is expanding our existing Dynamic FHIR API to support two options:
- Continue to use the CCD as the primary source of data for the FHIR resources, and
- Accepting a variety of data sources, including CCD, QRDA I, HL7 v2 ADT, and ORU messages, to build a FHIR data store.
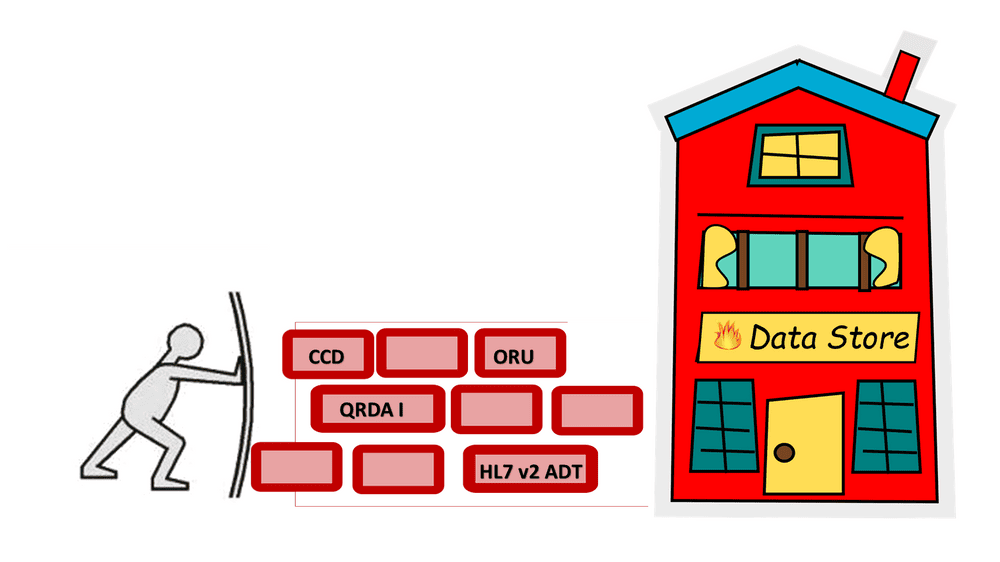
Option 1. expands our current “FHIR on the Fly” concept that relies on parsing “pulled” CCD data in response to a FHIR query and converting CCD data elements to FHIR resources.
Option 2. will consume “pushed” data, parsing it into a FHIR store in anticipation of future FHIR queries.
DHIT believes that certification is only the starting point for FHIR requirements and individual EHR implementations in conjunction with FHIR use cases will dictate whether a particular EHR prefers Option 1) or Option 2). One of our long-term goals entails creating one FHIR data store from multiple data resources to serve data to both our ConnectEHR and CQMsolution products.
Connectathon Scenarios
Scenario 1: Bulk data export with the retrieval of referenced files on an open endpoint
Data Provider and Data Consumer follow the flow outlined in the Bulk Data Export IG to generate and retrieve a dataset using one or more of the new capabilities in v1.1
Scenario 2: Bulk data export with the retrieval of referenced files on a protected endpoint
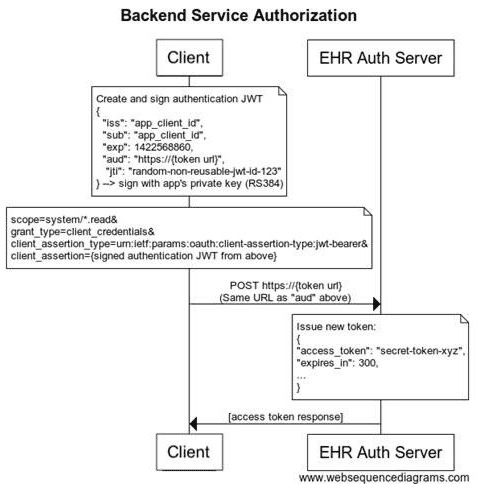
- Data Consumer registers with Data Provider, per SMART Backend Services Authorization rather than the patient access Authorization, used in (g)(9).
- Data Consumer obtains an access token, per SMART Backend Services Authorization
- Data Consumer follows the flow outlined in the Bulk Data Export IG to generate and retrieve a dataset using one or more of the new capabilities in v1.1, passing in the access token.
- Data Consumer attempts to retrieve a dataset using the flow outlined in the Bulk Data Export IG without providing a valid access token and fails.
Implementation Strategy and Future Goals
DHIT will collaborate closely with Electronic Health Record (EHR) systems to achieve compliance with requirement (g)(10), delivering customized solutions that address their specific needs. Robust authentication and security through SMART technology forms a cornerstone of our comprehensive solution.
Additionally, we have initiated the development of FHIR clients designed to retrieve data from county and government agency FHIR servers, integrating into client EHR systems. Following the Connectathon event, DHIT’s FHIR developer Sumanth Bandaru captured the essence of our progress perfectly:
“Bulk data export shines when there is a lot of data to retrieve and especially if the authorization and retrieval is normally a time-consuming process. The Bulk Export operation works in an asynchronous fashion. This can be used by EHR systems, data warehouses, and other clinical and administrative systems.”
For more detailed information on the Connectathon tracks and goals, see confluence.
For more information on the outcome of the Connectathon, click here.


